Recent Tutorials
Node.js for beginners - Callbacks
Hello, if you haven't checked out part 1 yet then go back and take a look. It's good, promise =)
So far we've covered how to do some basic things in Node.js, now we're going to take a look at callbacks and what makes them so useful.
Why Node.js?
There are many different programming languages available and they all have different strengths and weaknesses. Being able to compare languages and select the best one for your problem is an important step in building scalable and reliable products. Just like every other language Node.js has its strengths and weaknesses, but first let's take a look at when and why we would want to use Node.js.Strengths:
- Node.js is great if you need to handle loads of concurrent connections with little overhead. If you're going to be creating an application that needs to deal with thousands of requests then Node.js is definitely a good choice.
- It's JavaScript which means anyone who's ever used JavaScript on the client side can transfer their skill to Node.js. It's also built on Google's V8 JavaScript engine so it's pretty fast compared to with languages.
- If you're using JavaScript on both the client and server side it can make programming easier and quicker. For example if you have to validate some form data you can use the same code for the client and server. It's also makes it super easy to transfer data structures back and forth from and client and server.
- You'll impress your PHP scripting buddies!
Now let's take a look at some of the weaknesses.
Weaknesses:
- It's a new language and developers haven't had the time to create strong well tested modules for it just yet. It's worth noting there is also a lack of good IDEs, example code and support when compared to other, older languages. If you run into a problem you're unlikely to get as many search results and well documented solutions as you would for a problem in say, PHP. Although this is a disadvantage today, as Node.js becomes increasingly more popular amongst developers more resources will be available making it progressively quicker and easier to develop in.
- Code can get easily messy and confusing. To make your Node.js code run well you will need to use a lot of anonymous functions and callbacks (more on this in a bit!). These callbacks get increasingly deeper as your application gets larger resulting in the code being more complicated to read and debug.
- It's not the best number cruncher, but then neither is PHP or Ruby!
Blocking and non-blocking
Blocking is simply when your code can’t execute because something else is preventing it from running. This can happen because your application is waiting on another resource, for example, the CPU, network, memory or disk. To better explain how blocking can occur in your code let's take the following example:var http = require('http');
var url = require('url');
http.createServer(function (request, response) {
response.writeHead(200, {'Content-Type': 'text/plain'});
if( url.parse(request.url).pathname == '/wait' ){
var startTime = new Date().getTime();
while (new Date().getTime() < startTime + 15000);
response.write('Thanks for waiting!');
}
else{
response.write('Hello!');
}
response.end();
}).listen(8080);
console.log('Server started');
var url = require('url');
http.createServer(function (request, response) {
response.writeHead(200, {'Content-Type': 'text/plain'});
if( url.parse(request.url).pathname == '/wait' ){
var startTime = new Date().getTime();
while (new Date().getTime() < startTime + 15000);
response.write('Thanks for waiting!');
}
else{
response.write('Hello!');
}
response.end();
}).listen(8080);
console.log('Server started');
Save this code as “blocking.js” and run it with the command “node blocking.js”.
Here we're running a blocking script, a loop that runs for 15 seconds when the user calls ‘/wait’. Navigate your browser to http://localhost:8080/wait first, then straight after to http://localhost:8080 you should notice that even though the second script shouldn’t be running the blocking script, it still hangs. So why does this happen?
Node.js was designed to only use one thread; this makes it behave differently to a language like PHP, which creates a new thread for every new connection. If we’re dealing with all our requests within one thread any code that takes up 5 seconds of the CPU’s thread to run will stop our other requests for 5 seconds as well. Because we have to wait for our first request to finish before we can proceed; we call this code “blocking” due to our first request effectively “blocking” our second request from running.
So how can we stop this? Well first we need to make our code non-blocking, and do this we need to make use of callbacks.
What are callbacks?
If you’ve had any experience with JavaScript before, there’s a good chance you’ve seen callbacks already. The basic idea is that if we have to do something which could take a long time, let’s say we’re trying to read a large file, we don’t want our node.js server waiting around for the file to be read when it could be dealing with other incoming requests. So to deal with this we tell Node.js to do what it has to do in the background and to call a function when it’s finished. This way Node.js can carry on dealing with other requests while it’s reading the file, making our code non-blocking. When we have multiple things going on at the same time, like we have in our example, we can also call this code asynchronous.To help visualise how our non-blocking, asynchronous works, take the following example:
You’re driving down a narrow lane in your car but you can’t get where you want because there’s a car stopped in front while the driver is busy on his phone (our blocking code). Before you can continue, you’ll have to wait for the driver in front to finish what he is doing.
Now imagine there is a lay-by in this lane, the driver in front can now happily pull over into the lay-by to use his phone, leaving you room to pass and carry on with your journey. When he’s finished on his phone, he can carry along the lane, just as he would have before he pulled over. This is similar to how asynchronous code works; it allows multiple processes to happen at the same time, just how multiple cars can use our lane at the same time.
Lets use our new knowledge to create a non-blocking version of what we just did.
First lets put our blocking code in a new file.
var startTime = new Date().getTime();
while (new Date().getTime() < startTime + 10000);
while (new Date().getTime() < startTime + 10000);
Save the blocking code as "block.js".
Now lets create our server.
var http = require('http');
var url = require('url');
var cp = require('child_process');
function onRequest(request, response) {
var pathname = url.parse(request.url).pathname;
if( pathname == '/wait' ){
cp.exec('node block.js', myCallback);
}
else{
response.writeHead(200, {'Content-Type': 'text/plain'});
response.write('Hello!\n');
response.end();
}
console.log('New connection');
function myCallback(){
response.writeHead(200, {'Content-Type': 'text/plain'});
response.write('Thanks for waiting!\n');
response.end();
}
}
http.createServer(onRequest).listen(8080);
console.log('Server started');
var url = require('url');
var cp = require('child_process');
function onRequest(request, response) {
var pathname = url.parse(request.url).pathname;
if( pathname == '/wait' ){
cp.exec('node block.js', myCallback);
}
else{
response.writeHead(200, {'Content-Type': 'text/plain'});
response.write('Hello!\n');
response.end();
}
console.log('New connection');
function myCallback(){
response.writeHead(200, {'Content-Type': 'text/plain'});
response.write('Thanks for waiting!\n');
response.end();
}
}
http.createServer(onRequest).listen(8080);
console.log('Server started');
Here we're using the "child process" module so we can create a second Node thread allowing us to run our blocking code in the background. As it's in a new thread our main Node thread can continue on happily serving other incoming requests. We call .exec() function of the child process module to start the new thread and run our blocking script on. The .exec() function takes two parameters, the first is our node command to start our blocking script, and the second is our callback function. When our .exec() command has finished it runs the callback function, myCallback, and prints, 'Thanks for waiting!'.
To test it, save the code above as "nonblocking.js" then run it with the command, "node nonblocking.js".
You should notice that if you navigate to http://localhost:8080/wait and then to http://localhost:8080 we no longer have to wait for our blocking script to finish. Obviously this is a pointless example because our blocking script isn't doing anything worthwhile. So lets look at a slightly more interesting example of a non-blocking script we can create that uses callbacks.
Luckily for us Node.js comes with many non-blocking, asynchronous methods that we can easily implement into our applications. So let’s take a look at how to implement a non-blocking file reader into our code:
var http = require('http');
var fileSystem = require('fs');
http.createServer(function (request, response) {
response.writeHead(200, {'Content-Type': 'text/plain'});
var read_stream = fileSystem.createReadStream(‘myfile.txt');
read_stream.on('data', writeCallback);
read_stream.on('close', closeCallback);
function writeCallback(data){
response.write(data);
}
function closeCallback(){
response.end();
}
}).listen(8080);
console.log('Server started');
var fileSystem = require('fs');
http.createServer(function (request, response) {
response.writeHead(200, {'Content-Type': 'text/plain'});
var read_stream = fileSystem.createReadStream(‘myfile.txt');
read_stream.on('data', writeCallback);
read_stream.on('close', closeCallback);
function writeCallback(data){
response.write(data);
}
function closeCallback(){
response.end();
}
}).listen(8080);
console.log('Server started');
Here we’re using the file system module that's built into Node.js. We can call the file system's .createReadStream() method to read our file, and then attach a couple of callback functions onto the ‘data’ and ‘close’ events. These functions are then executed when the events are fired.
To try it for yourself save our code above as ‘fileReader.js’, then create a text file with some text output in, and save it as, "myfile.txt". Now you can run it with the command, "node fileReader.js". Navigate to http://localhost:8080 and you should see your file printed to the page.
Conclusion
Whenever you have a process that could take a long time to execute, you should always ensure that you're dealing with it in a non-blocking way. When implemented right, good use of callbacks and asynchronous code can provide huge improvements to the speed and scalability of your code.Feel free to add any comments or suggestions you have in the comments section.
Creating a genetic algorithm for beginners
Introduction
A genetic algorithm (GA) is great for finding solutions to complex search problems. They're often used in fields such as engineering to create incredibly high quality products thanks to their ability to search a through a huge combination of parameters to find the best match. For example, they can search through different combinations of materials and designs to find the perfect combination of both which could result in a stronger, lighter and overall, better final product. They can also be used to design computer algorithms, to schedule tasks, and to solve other optimization problems. Genetic algorithms are based on the process of evolution by natural selection which has been observed in nature. They essentially replicate the way in which life uses evolution to find solutions to real world problems. Surprisingly although genetic algorithms can be used to find solutions to incredibly complicated problems, they are themselves pretty simple to use and understand.How they work
As we now know they're based on the process of natural selection, this means they take the fundamental properties of natural selection and apply them to whatever problem it is we're trying to solve.The basic process for a genetic algorithm is:
- Initialization - Create an initial population. This population is usually randomly generated and can be any desired size, from only a few individuals to thousands.
- Evaluation - Each member of the population is then evaluated and we calculate a 'fitness' for that individual. The fitness value is calculated by how well it fits with our desired requirements. These requirements could be simple, 'faster algorithms are better', or more complex, 'stronger materials are better but they shouldn't be too heavy'.
- Selection - We want to be constantly improving our populations overall fitness. Selection helps us to do this by discarding the bad designs and only keeping the best individuals in the population. There are a few different selection methods but the basic idea is the same, make it more likely that fitter individuals will be selected for our next generation.
- Crossover - During crossover we create new individuals by combining aspects of our selected individuals. We can think of this as mimicking how sex works in nature. The hope is that by combining certain traits from two or more individuals we will create an even 'fitter' offspring which will inherit the best traits from each of it's parents.
- Mutation - We need to add a little bit randomness into our populations' genetics otherwise every combination of solutions we can create would be in our initial population. Mutation typically works by making very small changes at random to an individuals genome.
- And repeat! - Now we have our next generation we can start again from step two until we reach a termination condition.
Termination
There are a few reasons why you would want to terminate your genetic algorithm from continuing it's search for a solution. The most likely reason is that your algorithm has found a solution which is good enough and meets a predefined minimum criteria. Offer reasons for terminating could be constraints such as time or money.Limitations
Imagine you were told to wear a blindfold then you were placed at the bottom of a hill with the instruction to find your way to the peak. You're only option is to set off climbing the hill until you notice you're no longer ascending anymore. At this point you might declare you've found the peak, but how would you know? In this situation because of your blindfolded you couldn't see if you're actually at the peak or just at the peak of smaller section of the hill. We call this a local optimum. Below is an example of how this local optimum might look: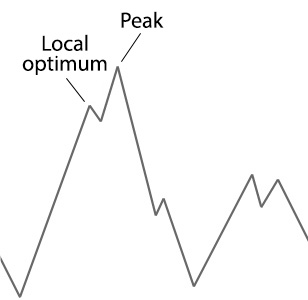
Unlike in our blindfolded hill climber, genetic algorithms can often escape from these local optimums if they are shallow enough. Although like our example we are often never able to guarantee that our genetic algorithm has found the global optimum solution to our problem. For more complex problems it is usually an unreasonable exception to find a global optimum, the best we can do is hope for is a close approximation of the optimal solution.
Implementing a basic binary genetic algorithm in Java
These examples are build in Java. If you don't have Java installed and you want to follow along please head over to the Java downloads page, http://www.oracle.com/technetwork/java/javase/downloads/index.htmlLet's take a look at the classes we're going to create for our GA:
- Population - Manages all individuals of a population
- Individual - Manages an individuals
- Algorithm - Manages our evolution algorithms such as crossover and mutation
- FitnessCalc - Allows us set a candidate solution and calculate an individual's fitness
Population.java
package simpleGa;
public class Population {
Individual[] individuals;
/*
* Constructors
*/
// Create a population
public Population(int populationSize, boolean initialise) {
individuals = new Individual[populationSize];
// Initialise population
if (initialise) {
// Loop and create individuals
for (int i = 0; i < size(); i++) {
Individual newIndividual = new Individual();
newIndividual.generateIndividual();
saveIndividual(i, newIndividual);
}
}
}
/* Getters */
public Individual getIndividual(int index) {
return individuals[index];
}
public Individual getFittest() {
Individual fittest = individuals[0];
// Loop through individuals to find fittest
for (int i = 0; i < size(); i++) {
if (fittest.getFitness() <= getIndividual(i).getFitness()) {
fittest = getIndividual(i);
}
}
return fittest;
}
/* Public methods */
// Get population size
public int size() {
return individuals.length;
}
// Save individual
public void saveIndividual(int index, Individual indiv) {
individuals[index] = indiv;
}
}
public class Population {
Individual[] individuals;
/*
* Constructors
*/
// Create a population
public Population(int populationSize, boolean initialise) {
individuals = new Individual[populationSize];
// Initialise population
if (initialise) {
// Loop and create individuals
for (int i = 0; i < size(); i++) {
Individual newIndividual = new Individual();
newIndividual.generateIndividual();
saveIndividual(i, newIndividual);
}
}
}
/* Getters */
public Individual getIndividual(int index) {
return individuals[index];
}
public Individual getFittest() {
Individual fittest = individuals[0];
// Loop through individuals to find fittest
for (int i = 0; i < size(); i++) {
if (fittest.getFitness() <= getIndividual(i).getFitness()) {
fittest = getIndividual(i);
}
}
return fittest;
}
/* Public methods */
// Get population size
public int size() {
return individuals.length;
}
// Save individual
public void saveIndividual(int index, Individual indiv) {
individuals[index] = indiv;
}
}
Individual.java
package simpleGa;
public class Individual {
static int defaultGeneLength = 64;
private byte[] genes = new byte[defaultGeneLength];
// Cache
private int fitness = 0;
// Create a random individual
public void generateIndividual() {
for (int i = 0; i < size(); i++) {
byte gene = (byte) Math.round(Math.random());
genes[i] = gene;
}
}
/* Getters and setters */
// Use this if you want to create individuals with different gene lengths
public static void setDefaultGeneLength(int length) {
defaultGeneLength = length;
}
public byte getGene(int index) {
return genes[index];
}
public void setGene(int index, byte value) {
genes[index] = value;
fitness = 0;
}
/* Public methods */
public int size() {
return genes.length;
}
public int getFitness() {
if (fitness == 0) {
fitness = FitnessCalc.getFitness(this);
}
return fitness;
}
@Override
public String toString() {
String geneString = "";
for (int i = 0; i < size(); i++) {
geneString += getGene(i);
}
return geneString;
}
}
public class Individual {
static int defaultGeneLength = 64;
private byte[] genes = new byte[defaultGeneLength];
// Cache
private int fitness = 0;
// Create a random individual
public void generateIndividual() {
for (int i = 0; i < size(); i++) {
byte gene = (byte) Math.round(Math.random());
genes[i] = gene;
}
}
/* Getters and setters */
// Use this if you want to create individuals with different gene lengths
public static void setDefaultGeneLength(int length) {
defaultGeneLength = length;
}
public byte getGene(int index) {
return genes[index];
}
public void setGene(int index, byte value) {
genes[index] = value;
fitness = 0;
}
/* Public methods */
public int size() {
return genes.length;
}
public int getFitness() {
if (fitness == 0) {
fitness = FitnessCalc.getFitness(this);
}
return fitness;
}
@Override
public String toString() {
String geneString = "";
for (int i = 0; i < size(); i++) {
geneString += getGene(i);
}
return geneString;
}
}
Algorithm.java
package simpleGa;
public class Algorithm {
/* GA parameters */
private static final double uniformRate = 0.5;
private static final double mutationRate = 0.015;
private static final int tournamentSize = 5;
private static final boolean elitism = true;
/* Public methods */
// Evolve a population
public static Population evolvePopulation(Population pop) {
Population newPopulation = new Population(pop.size(), false);
// Keep our best individual
if (elitism) {
newPopulation.saveIndividual(0, pop.getFittest());
}
// Crossover population
int elitismOffset;
if (elitism) {
elitismOffset = 1;
} else {
elitismOffset = 0;
}
// Loop over the population size and create new individuals with
// crossover
for (int i = elitismOffset; i < pop.size(); i++) {
Individual indiv1 = tournamentSelection(pop);
Individual indiv2 = tournamentSelection(pop);
Individual newIndiv = crossover(indiv1, indiv2);
newPopulation.saveIndividual(i, newIndiv);
}
// Mutate population
for (int i = elitismOffset; i < newPopulation.size(); i++) {
mutate(newPopulation.getIndividual(i));
}
return newPopulation;
}
// Crossover individuals
private static Individual crossover(Individual indiv1, Individual indiv2) {
Individual newSol = new Individual();
// Loop through genes
for (int i = 0; i < indiv1.size(); i++) {
// Crossover
if (Math.random() <= uniformRate) {
newSol.setGene(i, indiv1.getGene(i));
} else {
newSol.setGene(i, indiv2.getGene(i));
}
}
return newSol;
}
// Mutate an individual
private static void mutate(Individual indiv) {
// Loop through genes
for (int i = 0; i < indiv.size(); i++) {
if (Math.random() <= mutationRate) {
// Create random gene
byte gene = (byte) Math.round(Math.random());
indiv.setGene(i, gene);
}
}
}
// Select individuals for crossover
private static Individual tournamentSelection(Population pop) {
// Create a tournament population
Population tournament = new Population(tournamentSize, false);
// For each place in the tournament get a random individual
for (int i = 0; i < tournamentSize; i++) {
int randomId = (int) (Math.random() * pop.size());
tournament.saveIndividual(i, pop.getIndividual(randomId));
}
// Get the fittest
Individual fittest = tournament.getFittest();
return fittest;
}
}
public class Algorithm {
/* GA parameters */
private static final double uniformRate = 0.5;
private static final double mutationRate = 0.015;
private static final int tournamentSize = 5;
private static final boolean elitism = true;
/* Public methods */
// Evolve a population
public static Population evolvePopulation(Population pop) {
Population newPopulation = new Population(pop.size(), false);
// Keep our best individual
if (elitism) {
newPopulation.saveIndividual(0, pop.getFittest());
}
// Crossover population
int elitismOffset;
if (elitism) {
elitismOffset = 1;
} else {
elitismOffset = 0;
}
// Loop over the population size and create new individuals with
// crossover
for (int i = elitismOffset; i < pop.size(); i++) {
Individual indiv1 = tournamentSelection(pop);
Individual indiv2 = tournamentSelection(pop);
Individual newIndiv = crossover(indiv1, indiv2);
newPopulation.saveIndividual(i, newIndiv);
}
// Mutate population
for (int i = elitismOffset; i < newPopulation.size(); i++) {
mutate(newPopulation.getIndividual(i));
}
return newPopulation;
}
// Crossover individuals
private static Individual crossover(Individual indiv1, Individual indiv2) {
Individual newSol = new Individual();
// Loop through genes
for (int i = 0; i < indiv1.size(); i++) {
// Crossover
if (Math.random() <= uniformRate) {
newSol.setGene(i, indiv1.getGene(i));
} else {
newSol.setGene(i, indiv2.getGene(i));
}
}
return newSol;
}
// Mutate an individual
private static void mutate(Individual indiv) {
// Loop through genes
for (int i = 0; i < indiv.size(); i++) {
if (Math.random() <= mutationRate) {
// Create random gene
byte gene = (byte) Math.round(Math.random());
indiv.setGene(i, gene);
}
}
}
// Select individuals for crossover
private static Individual tournamentSelection(Population pop) {
// Create a tournament population
Population tournament = new Population(tournamentSize, false);
// For each place in the tournament get a random individual
for (int i = 0; i < tournamentSize; i++) {
int randomId = (int) (Math.random() * pop.size());
tournament.saveIndividual(i, pop.getIndividual(randomId));
}
// Get the fittest
Individual fittest = tournament.getFittest();
return fittest;
}
}
FitnessCalc.java
package simpleGa;
public class FitnessCalc {
static byte[] solution = new byte[64];
/* Public methods */
// Set a candidate solution as a byte array
public static void setSolution(byte[] newSolution) {
solution = newSolution;
}
// To make it easier we can use this method to set our candidate solution
// with string of 0s and 1s
static void setSolution(String newSolution) {
solution = new byte[newSolution.length()];
// Loop through each character of our string and save it in our byte
// array
for (int i = 0; i < newSolution.length(); i++) {
String character = newSolution.substring(i, i + 1);
if (character.contains("0") || character.contains("1")) {
solution[i] = Byte.parseByte(character);
} else {
solution[i] = 0;
}
}
}
// Calculate inidividuals fittness by comparing it to our candidate solution
static int getFitness(Individual individual) {
int fitness = 0;
// Loop through our individuals genes and compare them to our cadidates
for (int i = 0; i < individual.size() && i < solution.length; i++) {
if (individual.getGene(i) == solution[i]) {
fitness++;
}
}
return fitness;
}
// Get optimum fitness
static int getMaxFitness() {
int maxFitness = solution.length;
return maxFitness;
}
}
public class FitnessCalc {
static byte[] solution = new byte[64];
/* Public methods */
// Set a candidate solution as a byte array
public static void setSolution(byte[] newSolution) {
solution = newSolution;
}
// To make it easier we can use this method to set our candidate solution
// with string of 0s and 1s
static void setSolution(String newSolution) {
solution = new byte[newSolution.length()];
// Loop through each character of our string and save it in our byte
// array
for (int i = 0; i < newSolution.length(); i++) {
String character = newSolution.substring(i, i + 1);
if (character.contains("0") || character.contains("1")) {
solution[i] = Byte.parseByte(character);
} else {
solution[i] = 0;
}
}
}
// Calculate inidividuals fittness by comparing it to our candidate solution
static int getFitness(Individual individual) {
int fitness = 0;
// Loop through our individuals genes and compare them to our cadidates
for (int i = 0; i < individual.size() && i < solution.length; i++) {
if (individual.getGene(i) == solution[i]) {
fitness++;
}
}
return fitness;
}
// Get optimum fitness
static int getMaxFitness() {
int maxFitness = solution.length;
return maxFitness;
}
}
Now let's create our main class.
First we need to set a candidate solution (feel free to change this if you want to).
FitnessCalc.setSolution("1111000000000000000000000000000000000000000000000000000000001111");
Now we'll create our initial population, a population of 50 should be fine.
Population myPop = new Population(50,true);
Now we can evolve our population until we reach our optimum fitness
int generationCount = 0;
while(myPop.getFittest().getFitness() < FitnessCalc.getMaxFitness()){
generationCount++;
System.out.println("Generation: "+generationCount+" Fittest: "+myPop.getFittest().getFitness());
myPop = Algorithm.evolvePopulation(myPop);
}
System.out.println("Solution found!");
System.out.println("Generation: "+generationCount);
System.out.println("Genes:");
System.out.println(myPop.getFittest());
while(myPop.getFittest().getFitness() < FitnessCalc.getMaxFitness()){
generationCount++;
System.out.println("Generation: "+generationCount+" Fittest: "+myPop.getFittest().getFitness());
myPop = Algorithm.evolvePopulation(myPop);
}
System.out.println("Solution found!");
System.out.println("Generation: "+generationCount);
System.out.println("Genes:");
System.out.println(myPop.getFittest());
Here's the complete code for our main class:
GA.java
package simpleGa;
public class GA {
public static void main(String[] args) {
// Set a candidate solution
FitnessCalc.setSolution("1111000000000000000000000000000000000000000000000000000000001111");
// Create an initial population
Population myPop = new Population(50, true);
// Evolve our population until we reach an optimum solution
int generationCount = 0;
while (myPop.getFittest().getFitness() < FitnessCalc.getMaxFitness()) {
generationCount++;
System.out.println("Generation: " + generationCount + " Fittest: " + myPop.getFittest().getFitness());
myPop = Algorithm.evolvePopulation(myPop);
}
System.out.println("Solution found!");
System.out.println("Generation: " + generationCount);
System.out.println("Genes:");
System.out.println(myPop.getFittest());
}
}
public class GA {
public static void main(String[] args) {
// Set a candidate solution
FitnessCalc.setSolution("1111000000000000000000000000000000000000000000000000000000001111");
// Create an initial population
Population myPop = new Population(50, true);
// Evolve our population until we reach an optimum solution
int generationCount = 0;
while (myPop.getFittest().getFitness() < FitnessCalc.getMaxFitness()) {
generationCount++;
System.out.println("Generation: " + generationCount + " Fittest: " + myPop.getFittest().getFitness());
myPop = Algorithm.evolvePopulation(myPop);
}
System.out.println("Solution found!");
System.out.println("Generation: " + generationCount);
System.out.println("Genes:");
System.out.println(myPop.getFittest());
}
}
If everything's right, you should get an output similar to the following:
Generation: 1 Fittest: 40
Generation: 2 Fittest: 43
Generation: 3 Fittest: 50
Generation: 4 Fittest: 50
Generation: 5 Fittest: 52
Generation: 6 Fittest: 59
Generation: 7 Fittest: 59
Generation: 8 Fittest: 61
Generation: 9 Fittest: 61
Generation: 10 Fittest: 61
Generation: 11 Fittest: 63
Generation: 12 Fittest: 63
Generation: 13 Fittest: 63
Generation: 14 Fittest: 63
Generation: 15 Fittest: 63
Solution found!
Generation: 15
Genes:
1111000000000000000000000000000000000000000000000000000000001111
Generation: 2 Fittest: 43
Generation: 3 Fittest: 50
Generation: 4 Fittest: 50
Generation: 5 Fittest: 52
Generation: 6 Fittest: 59
Generation: 7 Fittest: 59
Generation: 8 Fittest: 61
Generation: 9 Fittest: 61
Generation: 10 Fittest: 61
Generation: 11 Fittest: 63
Generation: 12 Fittest: 63
Generation: 13 Fittest: 63
Generation: 14 Fittest: 63
Generation: 15 Fittest: 63
Solution found!
Generation: 15
Genes:
1111000000000000000000000000000000000000000000000000000000001111
Remember you're output isn't going to be exactly the same as above because of the inherent characteristics of a genetic algorithm.
And there you have it, that's a very basic binary GA. The great thing about a binary GA is that it is easy to represent any problem, although it might not always be the best way of going about it.
Want to apply a genetic algorithm to a real search problem? Check out the following tutorial, applying a genetic algorithm to the traveling salesman problem
Node.js for beginners, part 1 - Hello world, and a bit of fun!
Introduction
This is the first part in a series of tutorials I want to write on Node.js. I should make it clear that I'm no expert on Node.js, but a good way to check you understand something is to try to explain it to someone else. If you see something that you don't think is quite right please let me know so I can correct the mistake, I'll make sure to give you credit.I decided to learn Node.js recently due to its increasing popularity. The programming industry moves incredibly fast and it's dangerous to fall behind. Learning new languages is important because if you don't you're likely you'll get left behind and out of a job. Think about all of them flash developers who can't find any work anymore.
So lets begin with a little bit of information (blegh!).
Node.js is a server-side version of JavaScript. That means all the things all them cool things about JavaScript apply here. It also means if you're already quite familiar with JavaScript you're going to have a nice advantage. Node.js is only a few years old and that means even the people that have been working with it from the very beginning have only been using it for a few years. Compare this to how long some people have been writing in C. Being such a new language it also means there aren't many people out there who know it and that means from the simple rule of supply and demand your skill is worth more than your average PHP programmer.
Creating Hello World
Let's create a hello world. First head over to http://www.nodejs.org and download node.js. When it's installed and ready create a new JavaScript file with the following:console.log("Hello World");
Now save the file, call it something like "hello.js" and run it with the following command:
node hello.js
So you should get 'Hello World' appear in your terminal. That's all good but I'm sure more importantly you want to know how to print 'Hello World' to new HTTP connections.
Open back up your text editor and type:
var http = require('http');
http.createServer(function (request, response) {
response.writeHead(200, {'Content-Type': 'text/plain'});
response.end('Hello World\n');
}).listen(8080);
console.log('Server started');
http.createServer(function (request, response) {
response.writeHead(200, {'Content-Type': 'text/plain'});
response.end('Hello World\n');
}).listen(8080);
console.log('Server started');
Now save your file and run it with:
node hello.js
You should see 'Server started' in the terminal. Great! Now open your web browser and go to 'http://localhost:8080' you should see your 'Hello World' message.
Let's take a closer look at our code.
The first line is just getting the http module and saving it to the variable 'http'. The http is included with Node.js to make it easy for us to create Node.js applications.
We can then use the http module to create our http server by calling it's function 'createServer'. This function returns an object and takes a function in a parameter.
We're calling the function 'listen' on our new server object which takes in a numeric value which tells our server what port we want it to listen on. In our case we're using port 8080 which is why we connected our browser to http://localhost:8080
We also create a function and use it as a parameter for the 'createServer' function. This is quite a standard thing to do in JavaScript because functions can be parameters just like variables and objects can be. What's going to happen is that every time our server receives and new connection on port 8080 it's going to run our function we gave it. Interestingly the function we are passing to it is called an anonymous function, and it's called this because we don't give it a name.
You might have noticed our anonymous function takes two parameters, 'request' and 'response'. These parameters get passed to our anonymous function by the HTTP server when it receives a new connection. They are both objects which we can use in our response to the incoming request.
You notice the first thing we do is call the 'writeHead' function this lets us set the HTTP status as the first parameter and send some response headers as a second parameter. We're setting status code 200 which is telling our web browser everything's OK and we're also passing it a 'Content-Type' header which lets our browser know what we're sending it. In our case it's just plain text.
Next we're using the response object to write our 'Hello World'. We do this by simply calling it's write function and passing it our text. At this point we're done with our response so we tell the response object by calling its 'end' function.
Making our response more interesting
Hello world is pretty boring so let's do something a little more entertaining. We can create a user counter very easily in Node.js and we don't even need to use a database like we might do in PHP.Create a new JavaScript file called, 'counter.js' and type the following:
var http = require('http');
var userCount = 0;
http.createServer(function (request, response) {
console.log('New connection');
userCount++;
response.writeHead(200, {'Content-Type': 'text/plain'});
response.write('Hello!\n');
response.write('We have had '+userCount+' visits!\n');
response.end();
}).listen(8080);
console.log('Server started');
var userCount = 0;
http.createServer(function (request, response) {
console.log('New connection');
userCount++;
response.writeHead(200, {'Content-Type': 'text/plain'});
response.write('Hello!\n');
response.write('We have had '+userCount+' visits!\n');
response.end();
}).listen(8080);
console.log('Server started');
Now let's run it with the command,
node counter.js
When you navigate your browser to 'http://localhost:8080' you should now get a view counter.
Note: You might see the counter going up by two for each request, this is because your browser is requesting the favicon from the server (http://localhost:8080/favicon.ico).
You should also see that Node.js is logging each request it receives to the console.
The main thing we're doing here is setting a 'userCount' variable and incrementing on each request. We're then writing the 'userCount' in the response text.
In PHP to do the same thing you would need to save the information to something like a text file or database.
If you liked this tutorial check out part 2, Node.js for beginners - Callbacks